
¿Os habéis preguntado cómo comprimir una voz para publicidad? Nosotros os explicaremos cómo hacerlo en esta nueva entrada de nuestro blog.
Si algún post que hayamos publicado hasta ahora se lleva el primer premio por ser el más leído, ése es, sin duda, éste en el que damos unas pequeñas directrices sobre cómo ecualizar una voz. Decíamos en el artículo que no existe una máxima universal que podamos aplicar para ecualizar todas las voces de la misma manera, puesto que en el proceso intervienen diversos factores que difieren de una a otra grabación. La ecualización aportará unos matices que ayudarán a que nuestra voz suene más audible, pero para conseguir que una voz suene medianamente profesional no nos bastará sólo con ecualizarla. Intervienen otros procesos que, aunque tampoco deben ser de obligado cumplimiento (aunque sí la mayoría recomendables), nos ayudarán a obtener nuestro objetivo. Es por ello que hoy nos ocupamos de una etapa casi obligatoria en el procesado de la voz: la compresión.
Lo haremos de la forma más genérica y clara que podamos, sin entrar en demasiados detalles que os puedan confundir. Somos conscientes que obviaremos otros conceptos interesantes y emplearemos un lenguaje a veces demasiado simplista, corriendo el riesgo de caer en inexactitudes (que nos gustaría que destacarais vosotros, a modo de juego), pero hemos tomado esa determinación para que todos lo que empezáis en el mundo de la edición de audio tengáis una visión genérica de lo que es y cómo debemos comprimir una señal. Vamos allá!
¿Cómo comprimir una voz?
Un momento… para entender el significado de compresión, y antes de explicaros cómo comprimir una señal, debemos tener claro un concepto que utilizaremos en más de una ocasión: la dinámica.
Hablando de manera simple, entendemos por dinámica de un sonido y, en nuestro caso, de la voz, a las variaciones de intensidad/energía de ésta durante un determinado período de tiempo. Esto es, a la existencia de una mayor o menor diferencia de potencia sonora entre los pasajes más intensos y los más relajados de una locución. Así, por ejemplo, y exagerando los términos, diremos que la dinámica de la transmisión de un partido de fútbol en el que se combinan momentos de tensión con otros de máximo relax, será mucho más evidente que en la lectura de una noticia de un informativo, donde la intensidad de la locución suele ser lineal y apenas varía en el tiempo.
¿En qué consiste, pues, y para qué sirve comprimir una voz? pues a grandes rasgos para igualar a nuestro gusto los niveles de mínima y máxima intensidad sonora de una locución. Es decir, al comprimir una voz vamos a procurar que el nivel de potencia sonora sea más o menos homogéneo durante toda la grabación, aumentando los niveles de energía sonora de los pasajes más bajos y reduciendo los picos de máxima señal, evitando así la distorsión. En siguiente gráfico puedes observar el ejemplo con dos imágenes: la primera de ella con el audio sin comprimir, y el segundo extremadamente comprimido. ¿Ves la diferencia?
-

Audio comprimido
-

Audio no comprimido


¿Qué gano comprimiendo una voz?
Aquí haremos una diferenciación según el objetivo que persigamos:
- Si nuestro objetivo es que se escuche claramente hasta la última vocal de una locución, comprimiendo la voz conseguiremos una mayor unidad en su sonoridad (se escucharán todas las sílabas con una intensidad similar, aunque no necesariamente igual) y, por lo tanto, lograremos a priori una mejor audibilidad de ésta, “se escuchará mejor”.
- Sin embargo, trabajar con un compresor también nos brinda la posibilidad de dar un matiz más artístico o creativo a una voz. Así, cuando escuchamos jingles radiofónicos, o incluso publicidad, es fácil percibir un uso voluntariamente abusivo del compresor, “aplastando” la voz, aportando un valor artístico al conjunto de la producción. Debemos decir, sin embargo, que aplastar una voz y conseguir que suene agradable al oído no es, en absoluto, una tarea sencilla de conseguir, y corremos el riesgo de producir el efecto contrario en el oyente.
Muy bien, ahora ya sabemos en qué consiste comprimir y pensaréis… va, y cómo lo hago? bueno, pues eso lo veremos en otro post posterior, porque antes de mostraros una aplicación práctica queremos que tengáis una idea de qué es un compresor y cómo funciona.
¿Qué es y qué controles tiene un compresor?

Soft-Knee
Pues el compresor es ese aparato electrónico o digital capaz de procesar una señal de audio, para nosotros, la voz, con el que (y aquí introducimos un nuevo concepto) modificaremos el rango dinámico de nuestro audio. ¡Un momento! ¿Pero qué es eso del rango dinámico?
Entendemos por rango dinámico al margen o espacio sonoro existente entre el nivel de señal más alto, es decir, aquel punto donde un sonido “suena más fuerte”, con más energía, y el nivel de ruido de fondo que genera por si mismo cualquier sistema de audio (noise floor). Todo ese espacio, ese margen que nuestra señal será capaz de recorrer en el tiempo, lo llamaremos “rango dinámico”. Aquí podéis ver un gráfico:
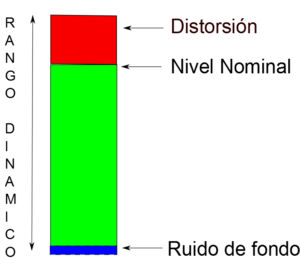
Como hemos visto, pues, cuando trabajamos con un compresor no hacemos otra cosa que controlar el rango dinámico de nuestra señal. Para ello, parametrizaremos los siguientes controles del compresor. Ojo, no todos los compresores son iguales (no explicaremos aquí las diferencias entre unos y otros), y por lo tanto, puede que nos encontremos con compresoras que dispongan de otros potenciómetros, además de los que os vamos a mostrar, o incluso es posible que sólo tengan algunos de estos. Pero como norma general, lo más probable es que nos encontremos con :
- Threshold (Umbral): Debe ser siempre nuestro punto de partida al comprimir. Es el primer elemento a tener en cuenta y desde el que iniciaremos todo el proceso. Con el regulador de Threshold le vamos a decir al compresor qué señales queremos que empiece a comprimir. Dicho de otro modo, le vamos a definir un umbral, un nivel de decibelios, que si es sobrepasado hará que nuestro compresor empiece a trabajar. Así, si definimos nuestro umbral en -10dB, cuando el audio se acerque a niveles de 0 dB (nivel nominal) por encima de ese límite (-9dB, -8db…) el compresor “despertará” y empezará a comprimir la señal. Y quizás os preguntéis… Pero… ¿puedo decidir qué cantidad de señal quiero comprimir? La respuesta es “sí”, con este regulador: el ratio.
- Ratio: Con este valor definiremos la proporción de señal que sobrepasará el nivel de Threshold que hayamos establecido. Por ejemplo, con un ratio de 5:1, estamos dando la orden que de cada 5dB que lleguen a nuestro Threshold, sólo 1db lo sobrepase. De este modo la potencia sonora de 5dB se reducirá a sólo 1 dB, y por consiguiente, la sensación de intensidad sonora será menor. Pero, y entonces, ¿siempre que una señal sobrepase el Threshold se comprimirá inmediatamente? Además, ¿y si me interesa que en mi voz suenen algunos picos, aunque sea ligeramente, para darle una sensación como de “chispa”? ¿Cómo lo hago? Pues muy sencillo, regulando el Ataque.
- Attack (ataque): este es el control con el que indicaremos el tiempo que tardará en actuar el compresor una vez la señal haya sobrepasado el umbral. Con un ataque muy rápido de, por ejemplo, por debajo de 350 us (microsegundos), el compresor reducirá todos los picos de señal, y posiblemente consigamos involuntariamente una reducción muy abrupta de la intensidad sonora, pudiendo generar en el oyente una sensación de caída de la misma. Por el contrario, con un ataque más lento, el compresor tardará un poco más en trabajar, y no comprimirá todos los transitorios, sólo algunos, lo que aportará más sensación de “chispa” a nuestra locución.
- Release (liberación): si el ataque es el tiempo que tarda nuestro compresor en empezar a trabajar cuando la señal sobrepasa el threshold, por el contrario, con el release decidimos cuándo nuestro compresor deja de trabajar la señal y la libera para regresar a su estado normal, cuando ésta ha bajado por debajo del nivel de threshold. Un release excesivamente rápido causará desajustes importantes de niveles y dinámica, y un release demasiado lento (de 1s, por ejemplo) hará que nuestra señal se siga comprimiendo durante más tiempo, llegando, incluso, a solaparse con la siguiente.
- Knee (codo/rodilla): Este parámetro no siempre aparece en todos los compresores, muchos ya lo integran de forma automática, pero nos lo encontraremos más de una vez. El knee es el control con el que configuraremos la “agresividad” o “delicadeza” con que nuestro compresor ataca la señal. Así, hay dos tipos de knee:
- Soft Knee: Es aquella configuración con la que la incidencia o compresión de nuestro dispositivo se realizará de una forma suave, no agresiva, gradual. Nos ayudará a que la sensación de cambio entre señal comprimida/no comprimida no sea tan evidente.
- Hard Knee: Al contrario que el anterior, este tipo de codo se suele utilizar cuando nuestra intención sea la de acentuar la diferencia entre la señal comprimida y no comprimida, normalmente empleada para señales con altos picos de intensidad sonora.
- Make Up Gain (Ganancia): Muy bien. Nuestra señal ya ha pasado por todas las fases de ajustes de compresión. Después de todo ello… ¿Cómo nos la encontramos? Pues igual que nosotros después de haber realizado una hora de ejercicios físicos: cansada, y algo débil. Es entonces cuando debemos reforzar y compensar esa pérdida de fuerzas. ¿Cómo? con la ganancia. Gracias a este control aumentaremos la potencia de nuestra señal (la escucharemos más fuerte) pero, ahora sí, sin los picos de volumen iniciales y con los sonidos más débiles reforzados. Auditivamente nos aportará una sensación de mayor homegeneidad sonora, notaremos como su presencia y energía habrá aumentado considerablemente.
Os mostramos un par de gráficos donde comprobar visualmente las funciones de estos parámetros:
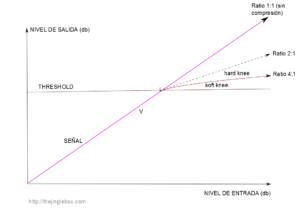
Cómo comprimir una voz – Threshold y Ratio – thejinglebox.com
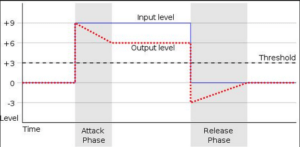
Cómo comprimir una voz – Attack y Release- thejinglebox.com
Por ahora creemos que ya es suficiente. Si es la primera vez que oís hablar de qué es y cómo funciona un compresor, y lo habéis entendido, nos damos por satisfechos. En un próximo post veremos cómo regular todos los controles, y veremos gráficamente y escucharemos ejemplos para comprobar de qué manera afectan a nuestra locución cada uno de los parámetros que acabamos de explicar.
¿Qué te ha parecido este artículo? puedes dejarnos tu opinión, criticarlo y compartirlo con tus contactos con los enlaces que encuentras a continuación.
Gracias, nos leemos muy pronto!
The JingleBox
muy buen post
me gusto mucho.
Quisiera saber si me pueden ayudar.
Que pasos se berian seguir para ecualizar correctamente la voz?
Primero le redusco el ruido de la voz
despues la ecualizo con un ecualizador de 30 bandas
luego agrego un de-eser
despues la comprimo pero no se escucha bien, se escucha un sonido como de telefono
¿que mas efectos de puedo agregar o quitar?
Hola Luis,
Gracias por seguir nuestro blog.
Respondiendo a tu pregunta, te invitamos a que leas este post, en el que damos unas pequeñas nociones de cómo ecualizar una voz.
Por lo que comentas, te recomendamos que utilices la máxima que utilizamos en audio, aquella de “menos, es más”… es decir, procura utilizar sutilmente los efectos que apliques a la voz. No siempre es necesario ecualizar una voz (aunque sí la mayoría de veces), comprimir, reducir ruido o aplicar un de-esser, puesto que es posible que consigas el efecto contrario del que estás buscando, como es en tu caso. Probablemente estés exagerando la ganancia en db al ecualizar o estés comprimiendo en exceso la voz. Es muy probable, incluso, que hayas recortado demasiadas frecuencias graves y agudas, potenciando así los medios y consiguiendo el típico efecto de filtro telefónico.
Pásate por nuestro post sobre ecualización, esperamos que te sirva de ayuda. 🙂
Gracias
exelente tu explicacion y entendida totalmente.como haria para leer tu opinion en el uso de atk y release en una locucion? SALUDOS.
Hola Arsenio,
Gracias por tu comentario. En breve publicaremos un nuevo artículo en el que profundizaremos sobre el uso del attack y el release en la locución publicitaria. Te invitamos a seguirnos.
Gracias y un saludo
Muy buen post!!! sigan así
Gracias Sergio!
Un saludo
Por fin una ayuda profesional para los trabajadores de la voz , hasta ahora teniamos que conformarnos con tutoriales de canto , donde rescatabamos algo para nuestra profesion de locutores, muchas gracias por el aporte
Muchas gracias a ti por tu comentario! nos alegra que te haya servido de ayuda 🙂
Saludos
Muy interesante. Estoy iniciando en la locución publicitaria. Y me gustaría seguir leyendo mas contenido sobre esta hermosa profesión.
Gracias